In an era marked by the rapid growth and increasing diversity of non-relational databases, the need for robust and adaptable database management tools has never been more crucial. At DBeaver, we’ve long supported a wide range of SQL and NoSQL data sources, each with its own unique challenges and opportunities. However, with Firestore, we faced a particularly complex task.

Our goal was to provide DBeaver users with seamless access to their Firestore data despite the complicated hierarchical structure of this database. Today, we will talk about this journey and what you can get from the new functionality.
Discovery and Current Capabilities
The non-relational database landscape has expanded significantly in recent years, with Firestore emerging as one of the most prominent players, particularly in mobile and web development. For example, according to a developer survey on StackOverflow, Firestore is used by 5.4% of respondents, below only the regular leaders like PostgreSQL, MySQL, and SQL Server, and above BigQuery, Snowflake, and others. Firestore’s structure is vastly different from traditional relational databases, as it organizes data in a document-based format within collections and subcollections. Recognizing the growing popularity of Firestore, especially among developers creating cross-platform applications, we understood the necessity of providing native support for this database in DBeaver.
Why DBeaver Provides Firestore Support
Our journey to support Firestore began with a request from our customer, Fivetran. They needed a way to efficiently manage Firestore data within DBeaver. We quickly realized that our existing methods were not compatible with Firestore’s hierarchical architecture. Unlike relational databases, Firestore does not use tables or rows, but instead relies on a nested structure of documents, collections and subcollections, which presented a unique challenge for us.
To provide effective Firestore support, we needed to rethink our approach from the ground up. Firestore’s real-time synchronization, offline capabilities, and automatic scaling features were all attractive to developers, but its structural differences required us to develop new tools and features within DBeaver to handle this complexity.
How the Development Team Met the Challenge
The challenge of integrating Firestore into DBeaver was significant, but it also presented an opportunity to innovate. Our development team focused on creating a solution that would not only meet the needs of our customers but also expand DBeaver’s overall functionality. We successfully implemented Firestore support and offered new capabilities.
What we did: Features of Firestore support
1. Grid Format Data ManagementWe started by implementing a way to view and edit Firestore data in a grid format. This was crucial because, although Firestore’s document-based structure is highly flexible, users needed a familiar interface to interact with the data. The grid format allows for a more intuitive management experience, making it easier to navigate and edit collections and documents within Firestore.
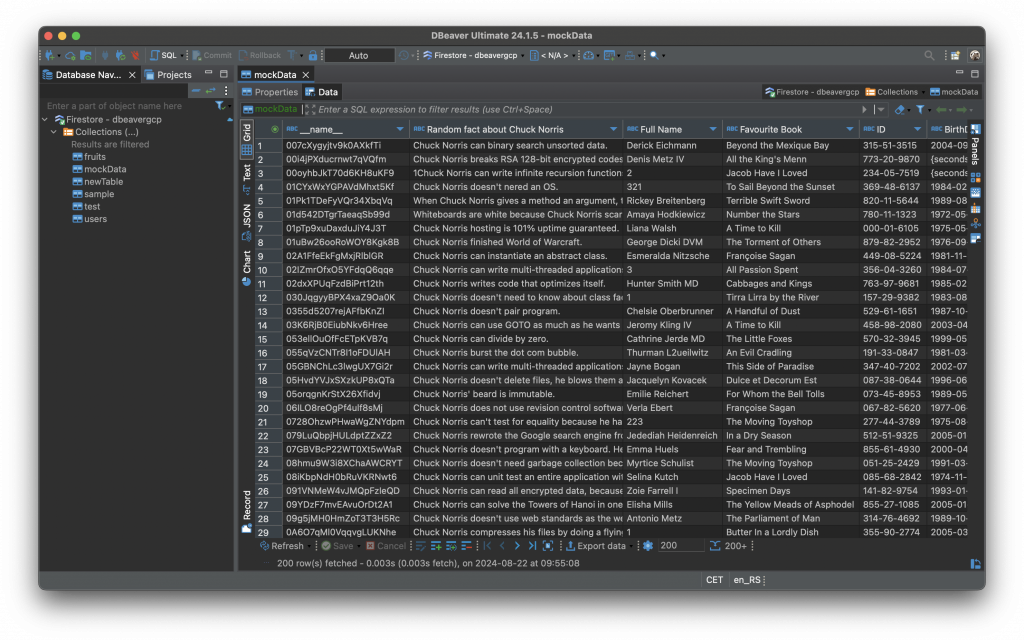
In Firestore, the unit of storage is the document – a lightweight record that contains fields which map to values. Each document is identified by a name. You may notice that documents look a lot like JSON. In fact, they basically are. There are some differences, but in general, you can treat documents as lightweight JSON records.
Given Firestore’s complex structure, it was essential to provide a robust JSON editor within DBeaver. Users can now view and edit Firestore data directly in JSON format, offering precise control over their data. This feature is consistent with our approach to other databases like Oracle or DocumentDB, where JSON data handling is also supported. The JSON view ensures that users have the flexibility to work with Firestore data in its native format, making DBeaver a versatile tool for developers.
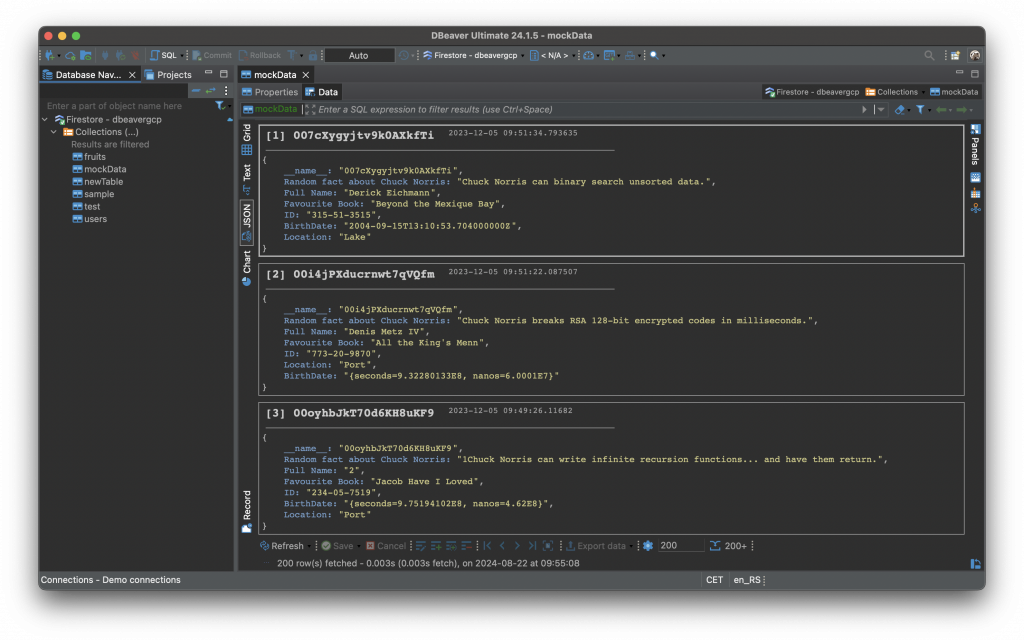
To switch to JSON View, find and click on the “JSON” button in the left sidebar to switch the current view to JSON. The Data Editor will now display the data in a raw JSON format, allowing you to edit the content directly.
3. Subcollection Access:One of the unique aspects of Firestore is its support for nested collections, or subcollections. To accommodate this, we introduced a new tab within DBeaver specifically for subcollections. This feature allows users to easily access and manage nested data structures, which is a critical aspect of working with Firestore. The subcollection tab streamlines the process of navigating through complex data hierarchies, making it easier to manage documents and their associated subcollections.
To create and manage subcollections in DBeaver, you first need to establish a connection to your Firestore database using DBeaver’s connection wizard. Once connected, navigate through the collections until you find the specific document that you wish to add to a subcollection. After selecting the document, direct your attention to the Panels bar on the right side of the Data Editor. This sidebar provides various tools for interacting with your data. Among these options, you will find a button labeled “Subcollection”. Clicking this button will open the Subcollection window, where you can work with any existing subcollections tied to the selected document.
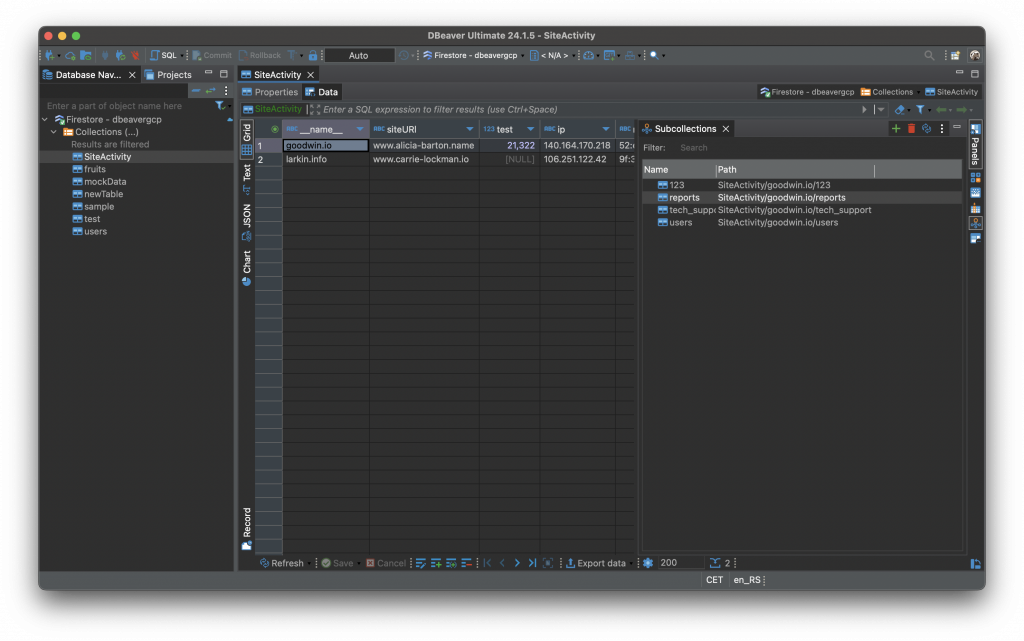
To create a new subcollection, simply click on the “Create Subcollection” within the Subcollection tab. You’ll be prompted to enter a name for the new subcollection. Once you’ve provided a name, the subcollection is immediately created under the selected document, and you can start adding documents to this subcollection just as you would in the main collection. The Subcollection tab allows you to manage these nested structures in the same way as top-level collections, offering options to view, edit, and delete documents within the subcollection.
The Subcollection tab in DBeaver provides a user-friendly and intuitive way to handle Firestore’s hierarchical data structures. It simplifies the process of navigating through and managing deeply nested data, ensuring that users can effectively work with their Firestore databases within DBeaver’s comprehensive interface.
Conclusion
Our experience integrating Firestore into DBeaver highlights the diversity of databases and the various approaches required to support them effectively. Each database comes with its own set of opportunities, and Firestore was no exception. However, by carefully analyzing these and developing tailored solutions, we were able to provide a comprehensive and user-friendly integration.
At DBeaver, we are committed to continuously improving our platform to meet our users’ evolving needs. The successful integration of Firestore is a testament to our dedication to providing comprehensive support for a wide range of databases. We encourage users to explore these new features and provide feedback, as your input is invaluable in helping us shape the future of DBeaver.