DBeaver is a versatile and cross-platform database management tool that supports a wide range of SQL and NoSQL databases, making it a useful tool for developers, DBAs, and data analysts.
DBeaver has mainly been used to manage batch data in databases and warehouses. However, with the integration of DBeaver and RisingWave, you can now also work with streaming data directly in DBeaver.

This integration is available from version 24.0 of DBeaver. With this new capability, you can easily ingest, transform, and visualize streaming data using DBeaver.
What is RisingWave?
RisingWave enables users to query and process streaming data using Postgres-style SQL. It leverages incremental computation algorithms to reduce latency and maintain the always up-to-date results in real-time materialized views.
Let’s see how the integration works.
How to connect to RisingWave in DBeaver
1. Ensure you have a RisingWave cluster running locally or on RisingWave Cloud. For more information, see RisingWave quick start or RisingWave Cloud documentation.
2. In DBeaver, select Database → New Database Connection.

3. Search and select RisingWave, and click Next.
4. In the window that opens, specify connection and authentication details. If you use a local RisingWave cluster, your connection information may look like below. If you use RisingWave Cloud, you can find the connection parameters from the Connect panel of your cluster.
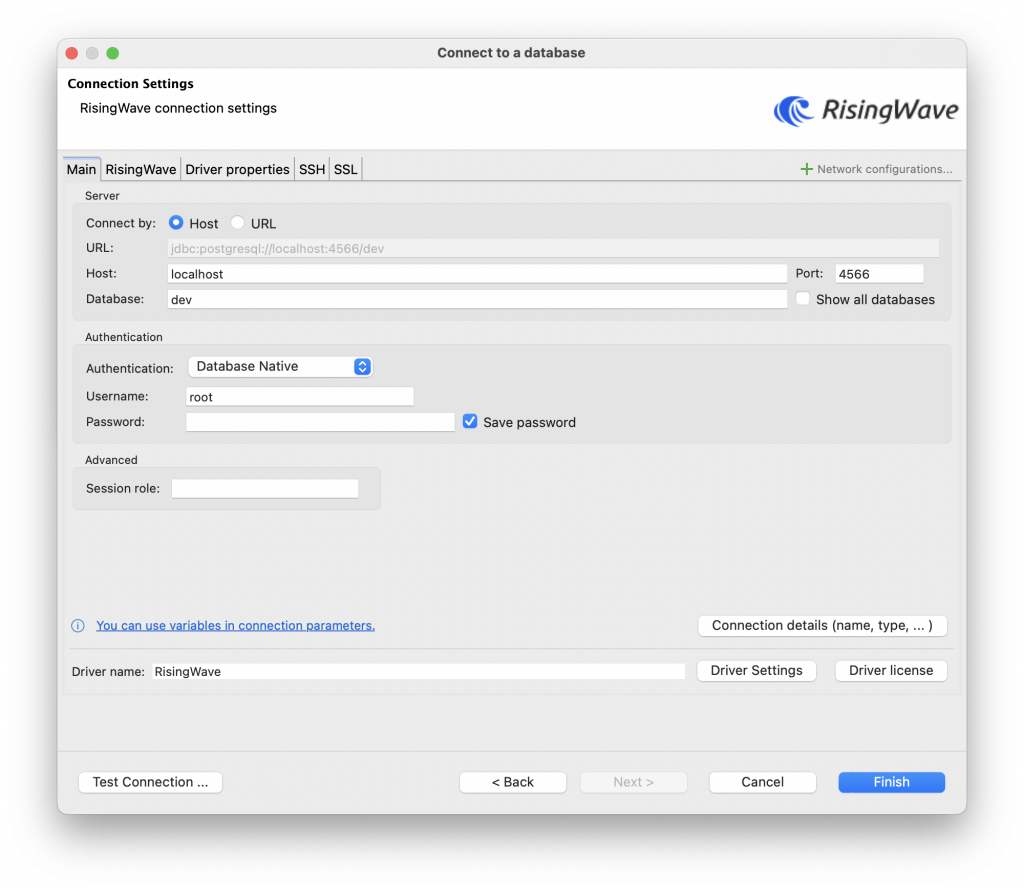
5. Click Finish to close the window. On the left panel in DBeaver, you’ll find the database that you just connected to via RisingWave driver.
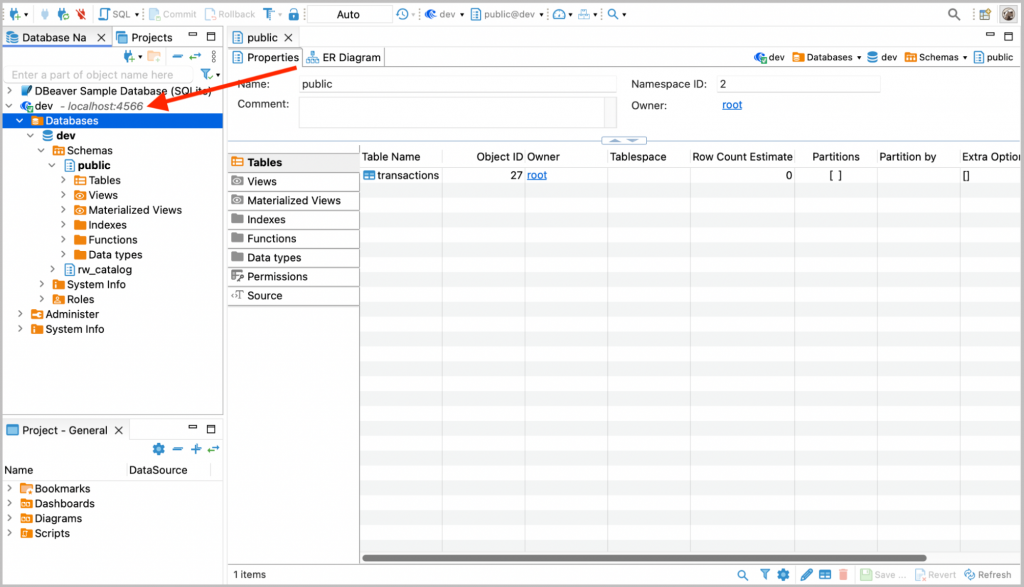
Now you can ingest streaming data from Kafka, Kinesis, or CDC streams from databases like PostgreSQL or MySQL, perform data filtering, joins, or transformations, and optionally deliver to your data warehouses or lakes. If your upstream and/or downstream systems are databases, you can manage them in DBeaver as well. That’s pretty handy in validating if data has come through.
Example
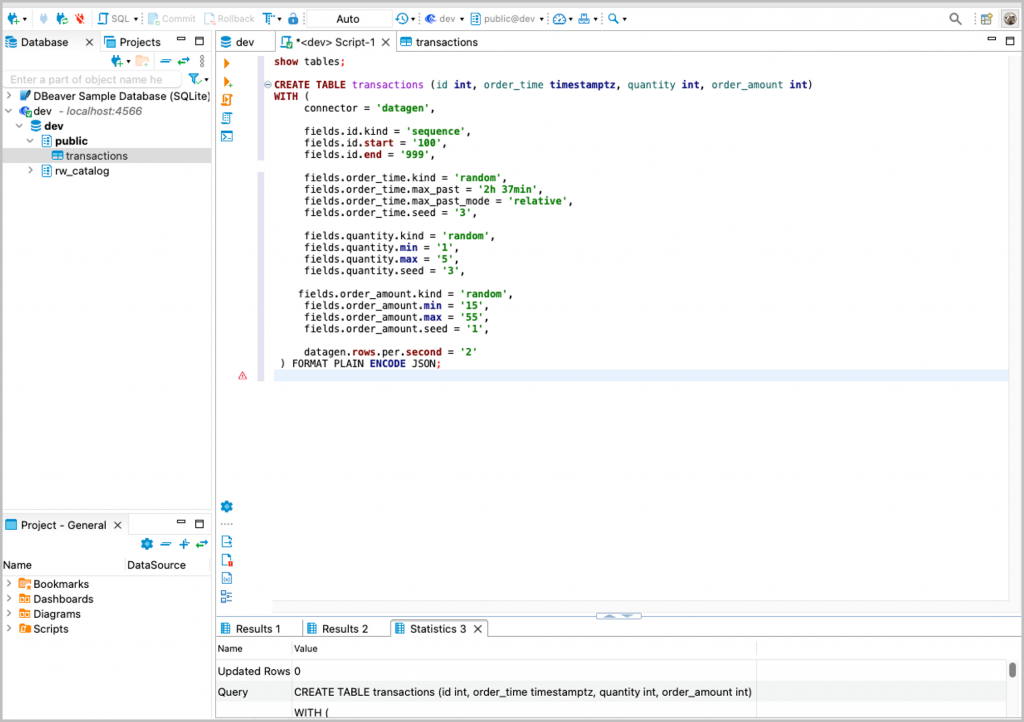
As an example, let’s create a streaming table in RisingWave. Note that new records will be generated as time goes by.
[cc lang=”SQL” width=”100%”] “`sql CREATE TABLE transactions (id int, order_time timestamptz, quantity int, order_amount int) WITH ( connector = ‘datagen’, fields.id.kind = ‘sequence’, fields.id.start = ‘100’, fields.id.end = ‘999’, fields.order_time.kind = ‘random’, fields.order_time.max_past = ‘2h 37min’, fields.order_time.max_past_mode = ‘relative’, fields.order_time.seed = ‘3’, fields.quantity.kind = ‘random’, fields.quantity.min = ‘1’, fields.quantity.max = ‘5’, fields.quantity.seed = ‘3’, fields.order_amount.kind = ‘random’, fields.order_amount.min = ’15’, fields.order_amount.max = ’55’, fields.order_amount.seed = ‘1’, datagen.rows.per.second = ‘2’ ) FORMAT PLAIN ENCODE JSON; “` [/cc]
We can then view the generated data in the Data view. As this is a table that holds streaming data, you’ll see new records come in every time you refresh the view.
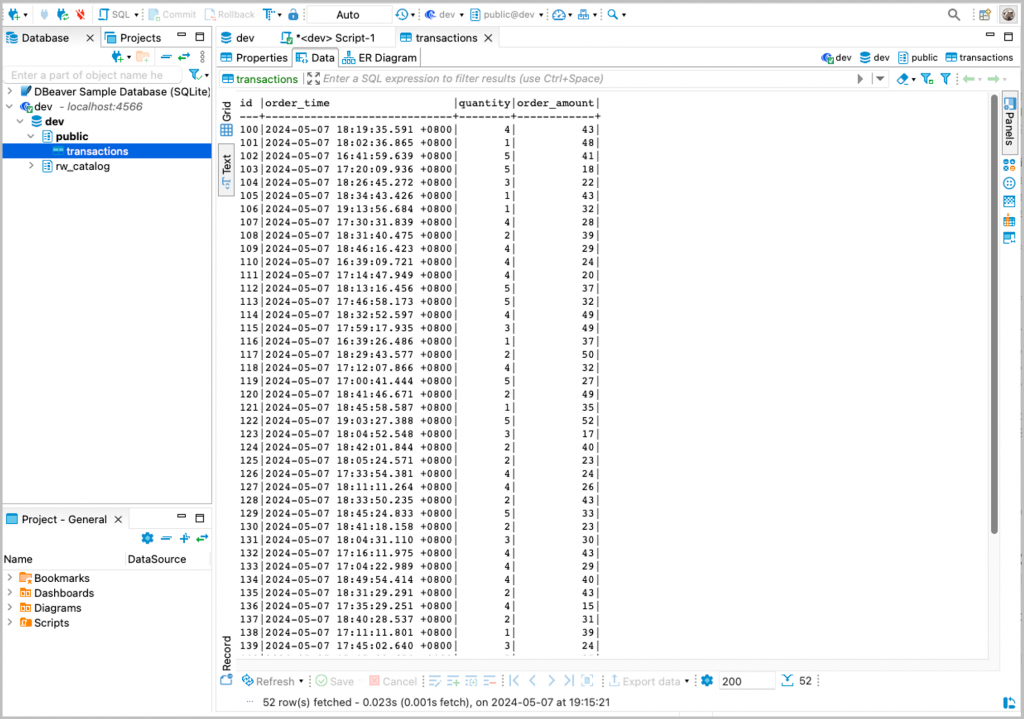
The SQL Script window is convenient if you need to tune your SQL query.
Why using DBeaver to connect to RisingWave?
By using DBeaver to connect to RisingWave, you have these potential benefits.
1. Unified Data Access: With the support of RisingWave within DBeaver, users gain a unified interface to access and manage both real-time streaming data and batch data. This eliminates the need to switch between different tools, streamlining the data management workflow.
2. Seamless Analytics: DBeaver’s powerful data analysis and visualization features can be directly applied to the real-time data streams processed by RisingWave. This allows users to gain insights and make data-driven decisions without the overhead of exporting data to external tools.
3. Comprehensive Data Integration: The integration enables users to view, process, and analyze their streaming data alongside other data sources within DBeaver. This provides a more holistic and contextual understanding of the data, which is particularly valuable for applications that require real-time data integration from multiple sources.
4. Automated Data Workflows: DBeaver’s automated workflow capabilities can be leveraged to create efficient data processing pipelines, including real-time data filtering, transformation, analysis, and visualization. This streamlines the data engineering and analysis processes, leading to increased productivity and faster time-to-insight.
5. Operational Efficiency: By consolidating streaming data processing and analysis within the DBeaver environment, users can reduce the complexity and maintenance overhead associated with managing multiple disparate tools. This integration promotes operational efficiency and simplifies the overall data infrastructure.