Apache Hive
This guide provides instructions on how to set up and use Apache Hive with DBeaver.
Before you start, you must create a connection in DBeaver and select Hive. If you have not done this, please refer to our Database Connection article.
DBeaver interacts with the Hive server using a specific driver. It supports all versions of Hive, but the
correct driver must be selected: use Hive 2 for versions 2.x and earlier, and Hive 4 for version 4 and later.
DBeaver also supports Hive extensions such as Kyuubi and Spark, depending on your environment
configuration. You must select the appropriate driver in the Connect to a database window for these extensions.
Tip
Systems like Impala use Hive-compatible drivers, so the standard Hive JDBC driver works in this case.
Apache Hive specialty¶
Apache Hive is a data warehouse system built on top of Hadoop for querying and analyzing large datasets using a SQL-like language called HiveQL. It's optimized for batch processing and is commonly used for data summarization, ad-hoc queries, and analysis of structured data. Hive translates SQL queries into MapReduce jobs, making it well-suited for handling large-scale data stored in Hadoop Distributed File System (HDFS). Hive is a good fit for OLAP-style workloads and integrates with other big data tools in the Hadoop ecosystem.
Info
For more detailed information and a comprehensive understanding of Apache Hive, see the official documentation.
Setting up¶
This section provides an overview of DBeaver's settings for establishing a direct connection and the configuration of secure connections using SSH and proxies for Hive.
Apache Hive connection settings¶
The page of the connection settings requires you to fill in specific fields to establish the initial connection.
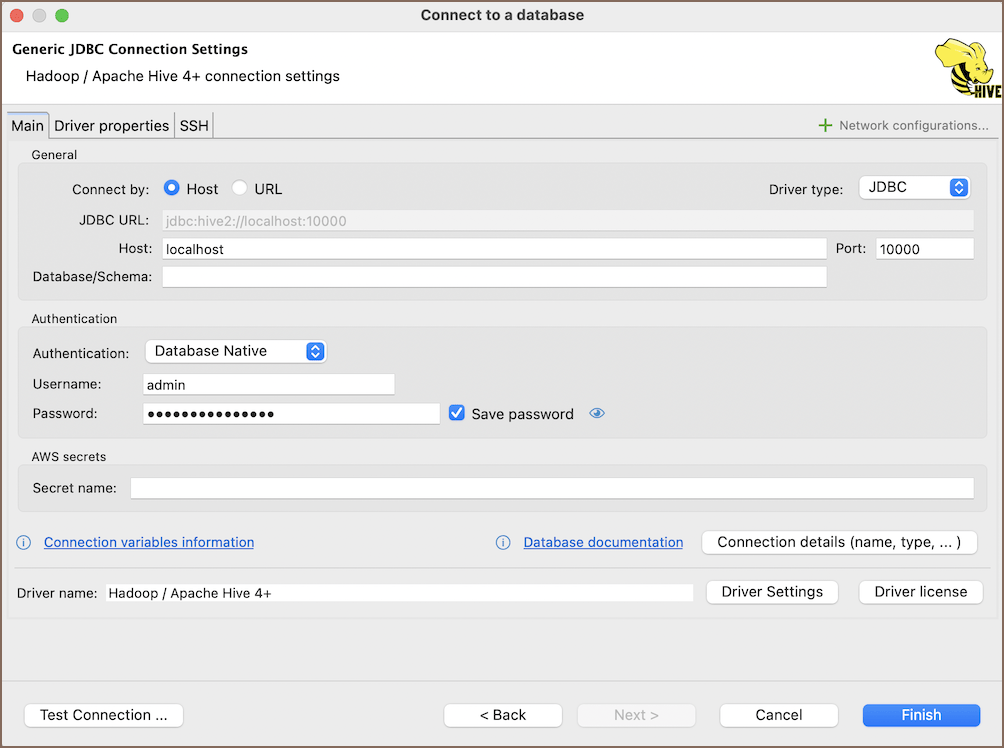
| Field | Description |
|---|---|
| Connect by (Host/URL) | Choose whether you want to connect using a host or a URL. |
| URL | If you are connecting via URL, enter the URL of your Hive database here. This field is hidden if you are connecting via the host. |
| Host | If you are connecting via host, enter the host address of your Hive database here. |
| Database/Schema | Enter the name of the Hive database you want to connect to. |
| Port | Enter the port number for your Hive database. The default Hive port is 10000. |
| Authentication | Choose the type of authentication you want to use for the connection. For detailed guides on authentication types, please refer to the following articles: - Username/password Authentication - DBeaver Profile Authentication  You can also read about security in DBeaver PRO. |
| Connection Details | Provide additional connection details if necessary. |
| Driver Name | This field will be auto-filled based on your selected driver type. |
| Driver Settings | If there are any specific driver settings, configure them here. |
Connection details¶
The Connection Details section in DBeaver allows you to customize your experience while working with Hive database. This includes options for adjusting the Navigator View, setting up Security measures, applying Filters, configuring Connection Initialization settings, and setting up Shell Commands. Each of these settings can significantly impact your database operations and workflow. For detailed guides on these settings, please refer to the following articles:
- Connection Details Configuration
- Database Navigator
- Security Settings Guide
- Filters Settings Guide
- Connection Initialization Settings Guide
- Shell Commands Guide
Apache Hive driver properties¶
The settings for Hive Driver properties enable you to adjust the performance of the Hive driver. These adjustments can influence the efficiency, compatibility, and features of your Hive database.
You can customize the Hive driver in DBeaver via the Edit Driver page, accessible by clicking on the Driver Settings button on the first page of the driver settings. This page offers a range of settings that can influence your Hive database connections. For a comprehensive guide on these settings, please refer to our Driver manager article.
Secure Connection Configurations¶
DBeaver supports secure connections to your Hive database. Guidance on configuring such connections, specifically SSH, Proxy, Kubernetes, and AWS SSM connections, can be found in various referenced articles. For a comprehensive understanding, please refer to these articles:
Secure Storage with Secret Providers¶
DBeaver supports various cloud-based secret providers to retrieve database credentials. For detailed setup instructions, see Secret Providers.
Powering Apache Hive with DBeaver¶
DBeaver provides a host of features designed for Hive databases. This includes the ability to view and manage databases, along with numerous unique capabilities aimed at optimizing database operations.
Apache Hive database objects¶
DBeaver lets you view and manipulate a wide range of Hive database objects. DBeaver has extensive support for various Hive metadata types, allowing you to interact with a wide variety of database objects, such as:
- Databases/Schemas
- Tables
- Columns
- Views
Info
Hive doesn’t support referential integrity, so you won’t see primary keys or foreign keys. Diagrams also aren’t relevant.
Apache Hive features¶
DBeaver is not limited to typical SQL tasks. It also includes features specific to Hive.
Beyond regular SQL operations, DBeaver provides a range of Hive-oriented capabilities, such as:
| Category | Feature |
|---|---|
| Data Types | Hive-specific types like ARRAY, STRUCT. |
| File System | HDFS. |
| Query Language | HiveQL (SQL-like query language). |
Additional features compatible with Hive, but not exclusive to it:
| Category | Feature |
|---|---|
| Data Transfer | Data Import |
| Data Export | |
| Data Management | Data Compare |