InfluxDB
Note
This driver is available in Lite, Enterprise, and Ultimate editions only.
DBeaver supports InfluxDB schema browser, data viewer and InfluxQL queries execution. DBeaver uses InfluxDB Java driver 2.12 to operate with the server over HTTP/HTTPS (standard InfluxDB protocol). It supports InfluxDB servers of any version (in the moment of writing).
Connecting to Influx Server¶
You can connect directly to a server or use SSH tunneling or SOCKS proxy.
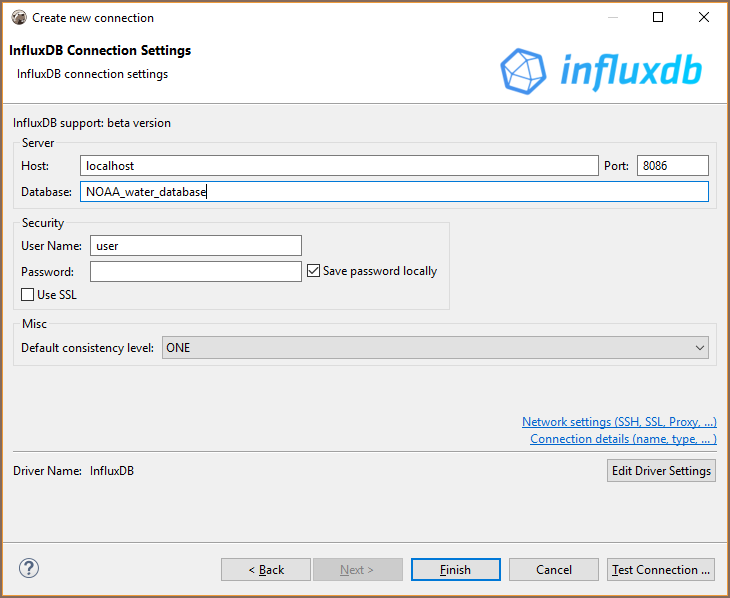
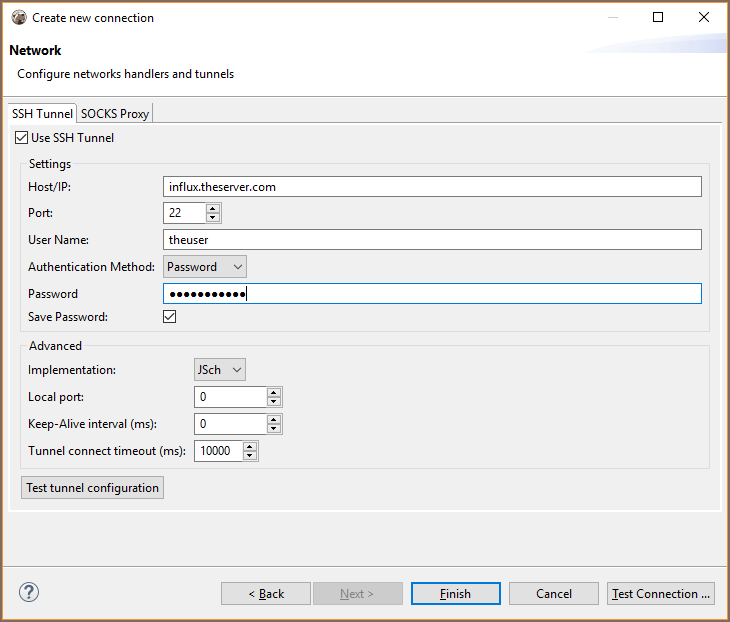
Browsing InfluxDB schema¶
InfluxDB is TimeSeries database, it does not support tables, foreign keys and other relational entities.
DBeaver does not support data insert/update in InfluxDB. Database is basically a in read-only state for DBeaver. You can browse schema and view/analyse data. While data itself is loaded by various sensors/data collectors in real time. Instead of tables InfluxDB has measurements. Instead of columns it has fields and tags.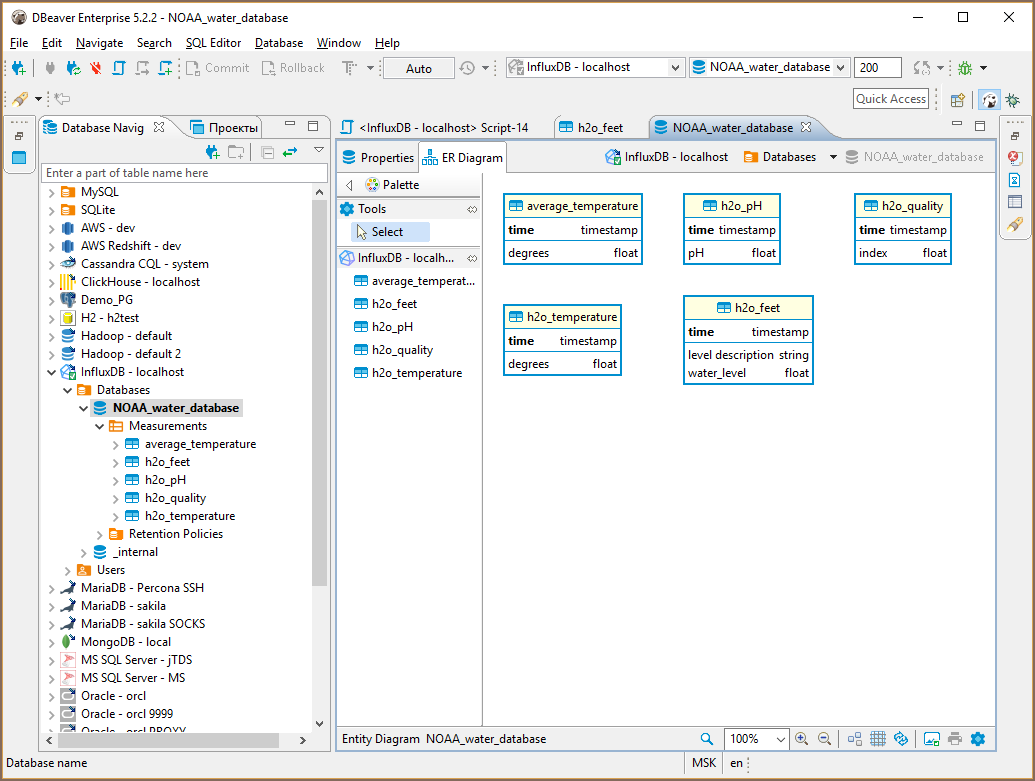
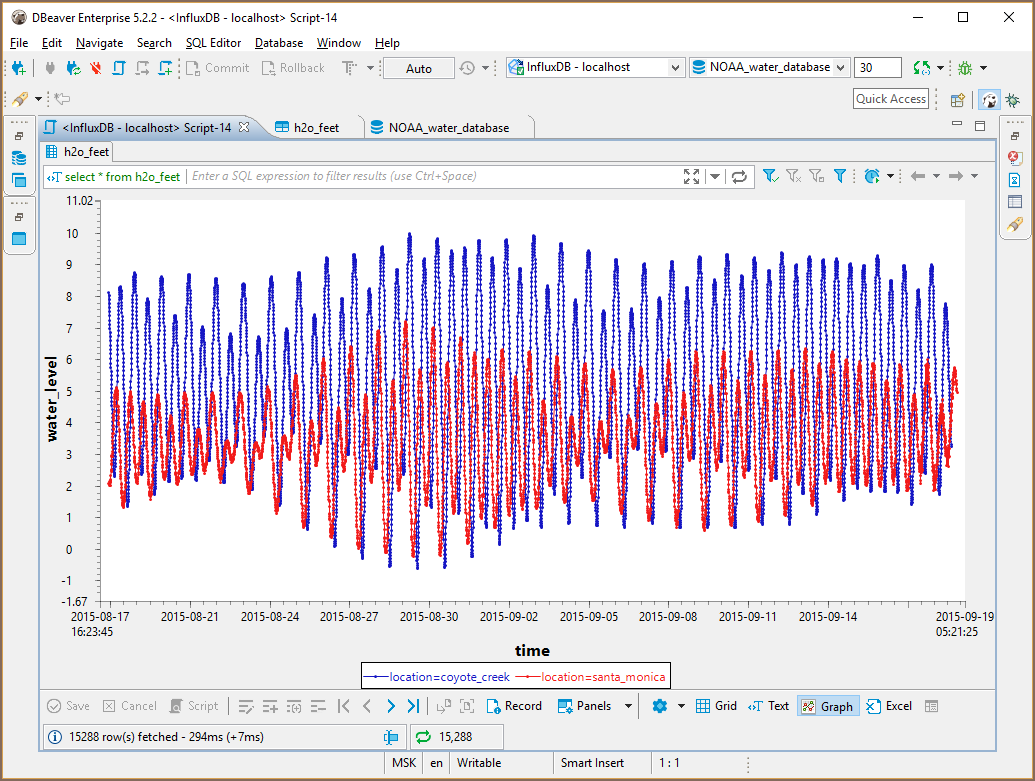
Executing InfluxQL¶
versions lower than 2
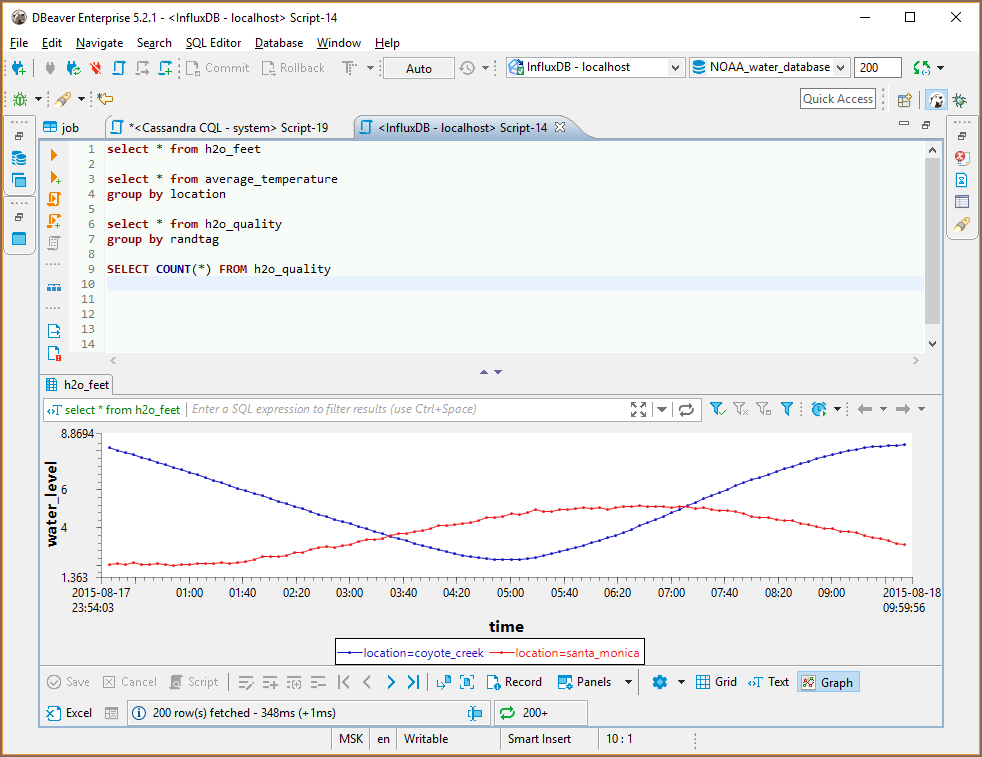
InfluxQL is a query language similar to SQL.
DBeaver fully supports all InfluxQL statements. Query results are presented as grid or as graphs:
Executing Flux¶
versions higher than 2 Flux is a query language that is used in the new versions of Influx. It is not similar to InfluxQL and doesn't use SQL syntax.